Advertisement
Scaling large language models has always come with trade-offs. As models grow bigger and more powerful, they also demand more memory, computing, and energy; for many developers and researchers, training or even running these models becomes a technical and financial challenge. One method that has helped reduce these costs without significantly affecting performance is 8-bit matrix multiplication.
This isn't a brand-new idea, but its application within modern transformer-based models—especially with libraries like Hugging Face Transformers, Accelerate, and bitsandbytes—makes it far more practical and efficient than before. This article takes a clear and grounded approach to explain how 8-bit precision helps with scaling transformers, how these tools fit together, and what they look like in real use.
Matrix multiplication is the backbone of transformer models. These operations happen constantly during training and inference—in attention layers, feedforward layers, and more. Normally, these multiplications are done using 16-bit or 32-bit floating-point numbers. This provides precision, but it's also expensive in terms of memory and computation. 8-bit matrix multiplication, as the name suggests, uses 8-bit integers instead. It reduces the memory footprint significantly and speeds up operations due to smaller data size and better utilization of hardware features.

Now, one might expect this to lower the model's performance. The key is that while inputs and outputs can stay in higher precision (like 16-bit or 32-bit), the internal matrix multiplication—the most resource-intensive part—can be done in 8-bit without hurting results much. This technique is a form of quantization and has been fine-tuned over time to minimize the accuracy loss.
The bitsandbytes library, developed by Tim Dettmers, implements a highly efficient version of 8-bit optimizers and matrix multiplication routines. It’s widely used in the community, especially for large model training and inference. Hugging Face’s ecosystem, with its Transformers and Accelerate libraries, integrates well with bitsandbytes, letting developers use these optimizations with minimal code changes.
When working with large models like LLaMA, Falcon, or GPT variants, loading them on a single GPU—or even across multiple GPUs—can hit a wall. Memory quickly becomes a bottleneck. Using bitsandbytes, one can load a model in 8-bit mode, allowing it to fit into a much smaller memory space. This is useful during inference but also has applications during training when using 8-bit optimizers.
Hugging Face Transformers provides model classes and pre-trained weights that are commonly used across research and industry. By default, models are loaded in 32-bit or sometimes 16-bit precision. But with just a few configuration tweaks, you can load them in 8-bit using bitsandbytes. This can cut memory usage by more than half in some cases.
The Accelerate library from Hugging Face further streamlines distributed training, mixed precision setups, and device placement. It removes much of the boilerplate needed to get models onto the right devices and can automatically handle integration with bitsandbytes. Together, Transformers, Accelerate, and bitsandbytes form a compact and efficient stack for running large-scale transformer models on consumer hardware.
To understand how this all works in practice, let’s walk through the core idea. Standard floating-point matrix multiplication involves two matrices with 16-bit or 32-bit numbers. These are multiplied and summed, requiring high memory bandwidth and compute power. Quantization converts these values to 8-bit integers before the multiplication. The multiplication itself is done in integer space, and then results can be dequantized—converted back to floating-point—for further processing.
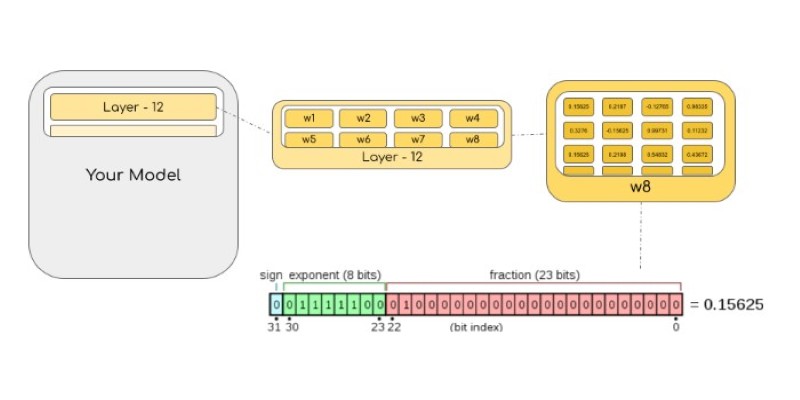
Quantization is not as simple as just converting numbers. It involves scaling and offset values to retain the range and distribution of the original data. In the context of bitsandbytes, the quantization is done dynamically per layer, and the scales are learned during training if needed. This allows the model to maintain good accuracy even with reduced precision.
There are different modes of 8-bit quantization: symmetric and asymmetric, static and dynamic. Bitsandbytes focuses on quantization techniques that work well for transformers, especially in scenarios where matrix weights can be pre-quantized and stored in 8-bit form. During inference, this means loading pre-quantized weights and running matrix multiplication in 8-bit directly. For training, it uses 8-bit optimizers that track gradients and weight updates in compressed form.
One standout feature of bitsandbytes is its support for quantizing only parts of the model selectively. For example, you might load the attention layers in 8-bit while keeping the output layer in full precision. This gives you control over the trade-off between performance and resource savings.
Let's say you want to load a popular transformer model, such as LLaMA or BLOOM, using Hugging Face in 8-bit. The process is straightforward. First, ensure you have the required libraries:
pip install transformers accelerate bitsandbytes
Then you can use this pattern:
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
model_name = "bigscience/bloom-1b1"
model = AutoModelForCausalLM.from_pretrained(
model_name,
load_in_8bit=True,
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained(model_name)
inputs = tokenizer("What's the capital of France?", return_tensors="pt").to(model.device)
outputs = model.generate(**inputs)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
Here, load_in_8bit=True triggers the use of bitsandbytes under the hood. The model loads in 8-bit precision, drastically reducing memory usage. device_map="auto" leverages Accelerate to place the model across available devices, whether it’s one or multiple GPUs.
This example shows how easy it is to adopt 8-bit inference without rewriting code or dealing with low-level details. This opens the door for running billion-parameter models on a single GPU with 16 GB or even less memory.
For training with 8-bit optimizers, you'd use similar patterns with Trainer or custom training loops, pointing to the 8-bit optimizers provided by bitsandbytes. The training process remains familiar but with improved efficiency and lower memory overhead.
8-bit matrix multiplication, paired with bitsandbytes, Hugging Face Transformers, and Accelerate, makes it easier to run large transformer models efficiently. It reduces memory and computing needs without much loss in performance. This approach allows developers to work with powerful models on more modest hardware. If you're using transformers, trying 8-bit precision could help you scale better while keeping costs and hardware requirements low. It’s practical and surprisingly effective.
Advertisement

Learn 5 simple steps to protect your data, build trust, and ensure safe, fair AI use in today's digital world.

Tired of reinventing model workflows from scratch? Hugging Face offers tools beyond Transformers to save time and reduce boilerplate

Find the 10 best image-generation prompts to help you design stunning, professional, and creative business cards with ease.

Explore the concept of LeRobot Community Datasets and how this ambitious project aims to become the “ImageNet” of robotics. Discover when and how a unified robotics dataset could transform the field
Advertisement
Explore Apache Kafka use cases in real-world scenarios and follow this detailed Kafka installation guide to set up your own event streaming platform

What happens when ML teams stop juggling tools? Fetch moved to Hugging Face on AWS and cut development time by 30%, boosting consistency and collaboration across projects

What happens when two tech giants team up? At Nvidia GTC 2025, IBM and Nvidia announced a partnership to make enterprise AI adoption faster, more scalable, and less chaotic. Here’s how
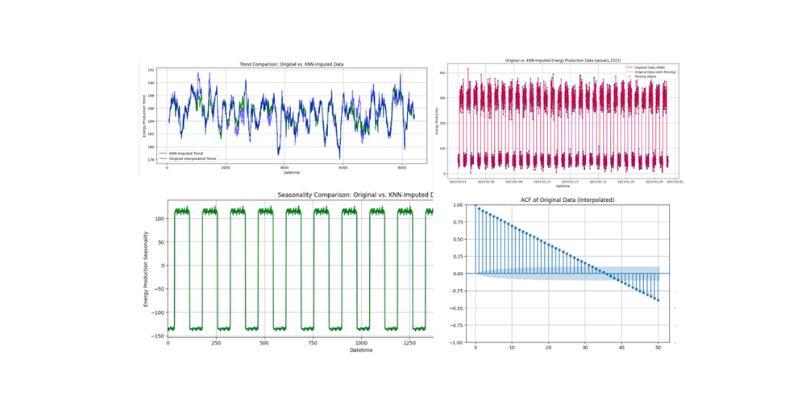
Discover effective machine learning techniques to handle missing data in time-series, improving predictions and model reliability
Advertisement

Find the top eight DeepSeek AI prompts that can accelerate your branding, content creation, and digital marketing results.

Intel and Hugging Face are teaming up to make machine learning hardware acceleration more accessible. Their partnership brings performance, flexibility, and ease of use to developers at every level

How the AI-enhancing quantum large language model combines artificial intelligence with quantum computing to deliver smarter, faster, and more efficient language understanding. Learn what this breakthrough means for the future of AI

How AI is transforming traditional intranets into smarter, more intuitive platforms that support better employee experiences and improve workplace efficiency