Advertisement
For developers at Fetch, managing machine learning projects used to mean dealing with scattered tools and redundant processes. Training models, running experiments, managing datasets—everything was handled through separate stacks, which often created silos within teams. While the tech worked, it wasn’t smooth. Most of the team time went into wiring things together instead of building what mattered. This wasn’t just inconvenient; it was slowing them down.
Now, that’s changed. After moving to Hugging Face on AWS, Fetch has not only consolidated its machine learning workflows into one place but also cut down its development time by 30%. This shift isn’t just a productivity win—it’s a sign of how thoughtful tool selection and smarter infrastructure choices can make machine learning work better for teams.
When a company like Fetch depends heavily on AI to improve product recommendations, customer interactions, and backend predictions, the pressure to get things right is high. But using too many tools can start to feel like trying to juggle with one hand tied. Fetch's developers had to spend time transferring models from one platform to another, juggling frameworks, and handling version mismatches. Sometimes, two teams solving the same problem were using entirely different pipelines without realizing it.
The hardest part wasn’t even writing the models—it was everything else around them. Training infrastructure didn’t always match the local testing environment. Version control was spread across different tools. Debugging a model in production meant retracing steps across multiple platforms.
In a setup like that, speed drops. Not because the team isn't skilled but because they're busy managing complexity.
Bringing everything into one place with Hugging Face on AWS gave Fetch something they didn’t have before—consistency. Now, training, fine-tuning, deployment, and scaling are handled from the same environment. Here’s what made the difference:

Before, training models meant setting up EC2 instances manually or using local resources and then migrating the model. That process took hours, sometimes days. Now, Fetch can train directly on SageMaker with pre-integrated Hugging Face containers. These containers come with the popular Transformers library and datasets pre-loaded, which cuts out all the setup.
Instead of building training environments from scratch, teams can focus on adjusting parameters and improving model logic. That’s where the real work should be.
Scaling a model up or down used to be a concern Fetch developers had to keep in mind. Hugging Face on AWS changes that by pairing models with SageMaker endpoints that scale automatically depending on demand. No manual instance tuning. No worries about under- or over-provisioning. Just consistent performance with less overhead.
This matters for any business serving live predictions. If an app goes from 10,000 users to 100,000, the infrastructure should keep up without a developer waking up at midnight to patch things up.
The Hugging Face Hub isn’t just a place to download public models—it's where Fetch's internal teams now host, share, and manage their own models, too. This single-source setup cuts the time spent syncing code, retraining the same models across different pipelines, or worrying about who has the most updated version.
It also helps in tracking experiments. Each change can be versioned, annotated, and reused. It's a quiet feature but a major time-saver when you're working across multiple squads.
Saving 30% development time wasn't a guess—it came from looking at the numbers. Projects that used to take around 10 weeks were getting completed in just under 7. That doesn't just help ship new features faster; it makes room for iteration. Teams can now test more ideas, refine models more often, and deliver smarter systems with fewer blockers.
This also helped onboarding. New developers didn't need to learn five different tools. With Hugging Face on AWS, the process became simple: learn one environment and get everything done.
In ML projects, small gains add up fast. By cutting out time spent on configuration, data movement, and environment management, Fetch could shift focus to the actual machine learning part. That’s where innovation happens, not in patching together environments or debugging tools that were never meant to work together.
A few months into the shift, the biggest change noticed by Fetch’s team wasn't just faster development—it was less frustration. Fewer Slack threads asking why something broke after being deployed. Less hunting for the right data format. Fewer one-off solutions that only work on one person’s laptop.
Instead of creating one pipeline per project, teams now reuse pre-built templates that live in the shared environment. A data scientist can jump into a project mid-way and understand the full setup in minutes, not days. When something breaks, logs are centralized, versions are clear, and tools speak the same language.
The Hugging Face tools integrate tightly with the AWS ecosystem, so Fetch didn’t have to rebuild its workflows from scratch. They just simplified what was already there. It’s not a shiny new solution—it’s a better version of what they were already trying to do, now with fewer handoffs and more direct control.
By shifting to Hugging Face on AWS, Fetch solved more than just a tooling issue. They cleared out the clutter, gave their teams one consistent workflow, and turned their attention back to what matters—building smarter AI solutions. The result was a 30% cut in development time, better team collaboration, and fewer points of failure.
The takeaway here isn’t that everyone needs to move their stack tomorrow. It’s that sometimes the best improvements come from less tool-switching, not more. And in a space like machine learning—where iteration speed often decides success—that’s a big win.
Advertisement

EY introduced its Nvidia AI-powered contract analysis at Mobile World Congress, showcasing how advanced AI and GPU technology transform contract review with speed, accuracy, and insight

How Nvidia produces China-specific AI chips to stay competitive in the Chinese market. Learn about the impact of AI chip production on global trade and technological advancements

How Amazon S3 works, its storage classes, features, and benefits. Discover why this cloud storage solution is trusted for secure, scalable data management

What happens when ML teams stop juggling tools? Fetch moved to Hugging Face on AWS and cut development time by 30%, boosting consistency and collaboration across projects
Advertisement

Learn the top 8 Claude AI prompts designed to help business coaches and consultants boost productivity and client results.

AI content detectors don’t work reliably and often mislabel human writing. Learn why these tools are flawed, how false positives happen, and what smarter alternatives look like

Intel and Hugging Face are teaming up to make machine learning hardware acceleration more accessible. Their partnership brings performance, flexibility, and ease of use to developers at every level

How machine learning is transforming sales forecasting by reducing errors, adapting to real-time data, and helping teams make faster, more accurate decisions across industries
Advertisement
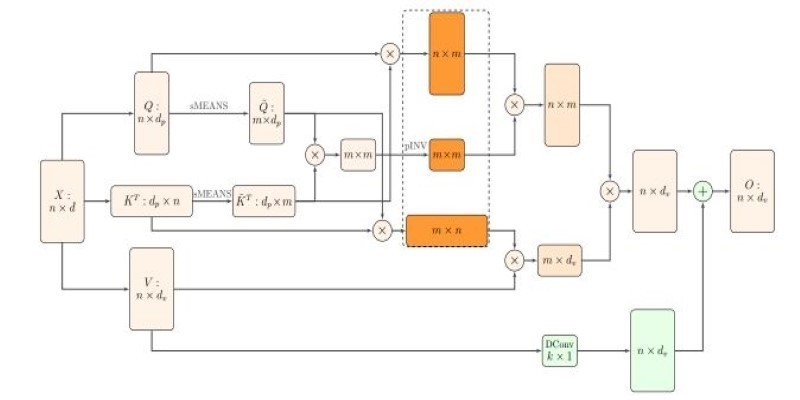
How Nyströmformer uses the Nystrmmethod to deliver efficient self-attention approximation in linear time and memory, making transformer models more scalable for long sequences

How 8-bit matrix multiplication helps scale transformer models efficiently using Hugging Face Transformers, Accelerate, and bitsandbytes, while reducing memory and compute needs

Find how AI is reshaping ROI. Explore seven powerful ways to boost your investment strategy and achieve smarter returns.

Ahead of the curve in 2025: Explore the top data management tools helping teams handle governance, quality, integration, and collaboration with less complexity