Advertisement
Data is being produced today at an astonishing rate — from apps, websites, sensors, transactions, and much more. For organizations that want to store all this information in its raw form and decide later how to use it, data lakes have become an important approach. A data lake is not just another storage solution; it is a flexible way to collect vast amounts of structured, semi-structured, and unstructured data without forcing it into predefined formats. This makes it appealing for analytics, machine learning, and innovation, as it preserves the richness of the original data for future exploration.
A data lake is a centralized repository where you can store data exactly as it is, at any scale. Unlike traditional databases or data warehouses that require data to be cleaned and organized before storage, a data lake allows you to keep data in its original format until you’re ready to process it. This is particularly useful when you’re not yet sure how the data might be used later.
Data lakes support all types of data: structured data like tables from databases, semi-structured data like JSON files, and unstructured data like images, audio, and video. This wide scope means you don’t lose information during ingestion, which often happens when data has to fit into rigid schemas. The flexibility to work with many kinds of data side by side makes a data lake suitable for both current analysis and future, unplanned projects.
Typically built on inexpensive, scalable storage systems, data lakes are commonly used in cloud environments, though they can also be set up on-premises. Open formats and compatibility with many analytics tools allow teams to extract insights without being tied to one technology.
Building and working with a data lake involves several clear steps, each focused on preserving the integrity of raw data while keeping it ready for analysis. Let’s break it down.
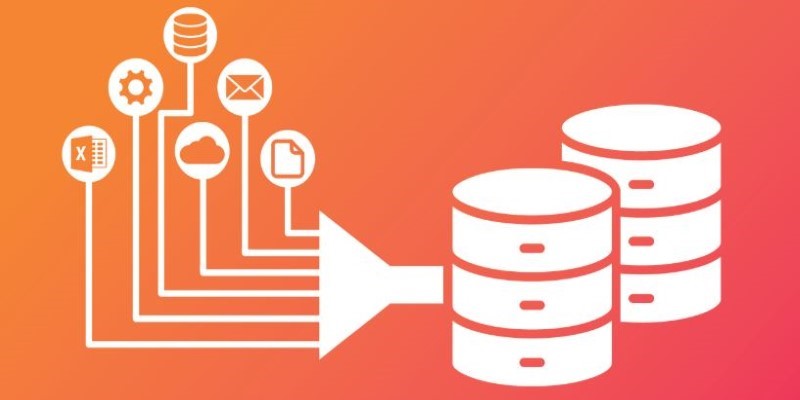
The first step is getting data into the lake. You can ingest data from many different sources, such as operational databases, log files, streaming data from sensors, social media feeds, or third-party APIs. This process can happen in real-time or in batches, depending on how quickly the data is needed. Importantly, no transformation happens yet — the data arrives exactly as it was generated. This makes the ingestion process fast and less prone to errors, and ensures that no potentially useful detail is discarded early on.
Once ingested, the data sits in the lake, usually organized in folders or object storage buckets. At this stage, the data may look messy, but that's expected — the value of the lake lies in preserving its raw state. The storage system must be designed to handle massive volumes, and cloud platforms like Amazon S3, Google Cloud Storage, and Azure Data Lake Storage are common choices for their durability and scalability. It's also possible to partition data logically, making it easier to find and process later without imposing a strict structure.
When you need to analyze the data, you extract relevant portions from the lake and process them. This is where you clean, transform, and enrich the data to fit the specific use case. This step is sometimes called ETL (extract, transform, load) or ELT (extract, load, transform), depending on the workflow. Unlike a warehouse where transformation happens before storage, here it’s done on-demand. Processing tools like Apache Spark, Hadoop, or cloud-native services help clean the data, join datasets, and prepare it for analytics or machine learning.
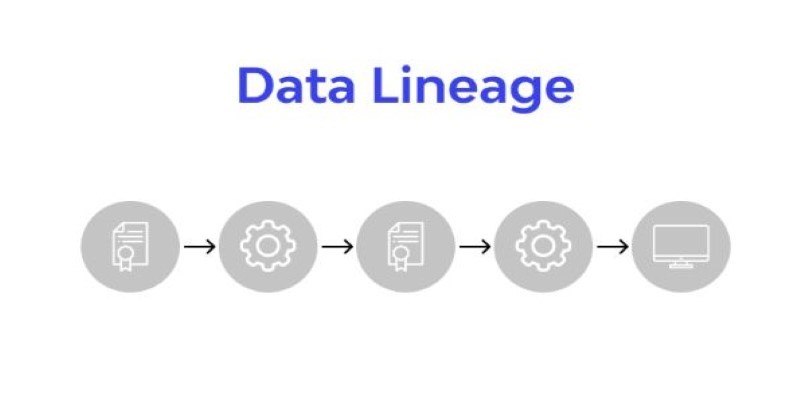
Because data lakes store such a variety of information, it’s important to have a way to keep track of what’s in there. This is where metadata management and cataloging come in. Catalogs describe each dataset, making it searchable and understandable to users. They also include data lineage information — where the data came from, when it was updated, and how it has been used — which helps maintain trust in the data. Security policies are also applied here to control who can access sensitive or regulated data.
The final step is extracting insights. Analysts, data scientists, and engineers can now connect analytics and machine learning tools directly to the data lake or work with prepared datasets. Since the data lake retains raw details, you can apply different analytical models or explore questions you didn’t anticipate when the data was first collected. This adaptability is one of the main reasons data lakes are widely adopted.
Data lakes bring some clear benefits. They store all kinds of data without losing richness or variety, and they scale cost-effectively as your data grows. They allow you to keep up with unpredictable and fast-changing data needs, letting you decide later what’s useful. They’re also a good foundation for advanced analytics and machine learning, which often require large and varied datasets.
However, there are challenges to be aware of. Without good management, a data lake can turn into a “data swamp,” where disorganized, undocumented data piles up and becomes hard to use. This is why cataloging, metadata, and governance are critical. Performance can also be slower for queries compared to a structured warehouse, since the raw data often needs processing first. Thoughtful planning and ongoing maintenance help keep a data lake functional and valuable over time.
A data lake is more than just storage — it’s a flexible approach to collecting and preserving data in its original form, ready for whatever questions the future might bring. Unlike traditional systems that require decisions about format and structure upfront, a data lake lets you keep everything as it comes and decide later how to use it. This makes it well-suited to modern, data-driven projects where speed and adaptability matter. With proper management, a data lake can help teams unlock insights and make better use of their data, no matter how fast it grows or how unpredictable the needs become.
Advertisement

The future of robots and robotics is transforming daily life through smarter machines that think, learn, and assist. From healthcare to space exploration, robotics technology is reshaping how humans work, connect, and solve real-world challenges

Learn how to use ChatGPT for customer service to improve efficiency, handle FAQs, and deliver 24/7 support at scale

Yamaha launches its autonomous farming division to bring smarter, more efficient solutions to agriculture. Learn how Yamaha robotics is shaping the future of farming

Rockwell Automation introduced its AI-powered digital twins at Hannover Messe 2025, offering real-time, adaptive virtual models to improve manufacturing efficiency and reliability across industries
Advertisement

Tired of reinventing model workflows from scratch? Hugging Face offers tools beyond Transformers to save time and reduce boilerplate
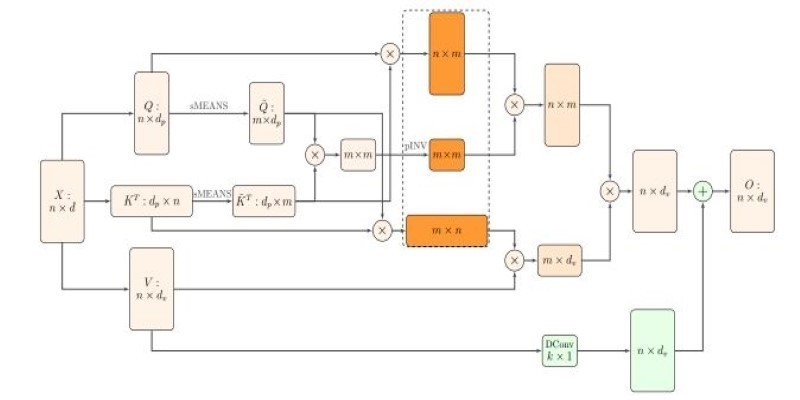
How Nyströmformer uses the Nystrmmethod to deliver efficient self-attention approximation in linear time and memory, making transformer models more scalable for long sequences

How the OpenAI jobs platform is changing the hiring process through AI integration. Learn what this means for job seekers and how it may reshape the future of work

How AI is transforming traditional intranets into smarter, more intuitive platforms that support better employee experiences and improve workplace efficiency
Advertisement

How Gradio reached one million users by focusing on simplicity, openness, and real-world usability. Learn what made Gradio stand out in the machine learning community

Discover 7 Claude AI prompts designed to help solo entrepreneurs work smarter, save time, and grow their businesses fast.

How machine learning is transforming sales forecasting by reducing errors, adapting to real-time data, and helping teams make faster, more accurate decisions across industries
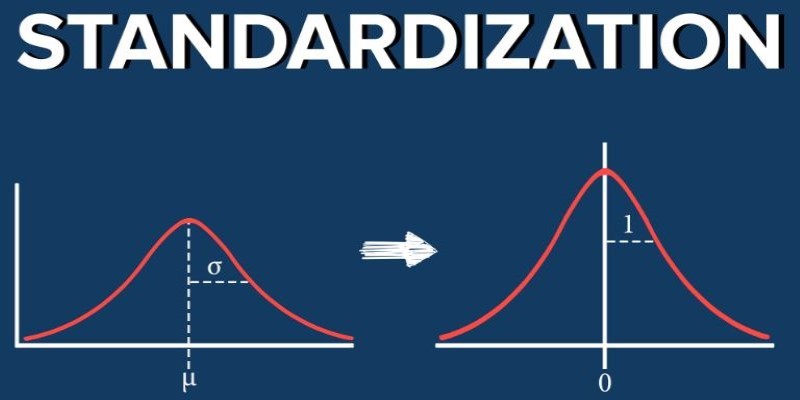
What standardization in machine learning means, how it compares to other feature scaling methods, and why it improves model performance for scale-sensitive algorithms