Advertisement
Text generation has taken on new speed and scale with Hugging Face, making its Text Generation Inference (TGI) available for AWS Inferentia2. This pairing brings optimized hardware and software together in a way that allows developers and businesses to run large language models without draining time or compute budgets. It's less about tweaking models to fit constraints and more about running them as they were meant to be — smoothly and at scale.
At the heart of this development is the need for efficiency. As models grow, so do their hardware requirements. Inference – that is, the act of generating text from a trained model – has often been the part of the AI pipeline that slows things down. Not anymore.
While training a model may occur over days or even weeks, it's only done once. Inference, on the other hand, occurs each time a user inquires about a model or provides it with a prompt. That makes it continuous, and if not managed well, it can get pricey or slow — or maybe even both.
This is where Hugging Face’s TGI steps in. It is designed to streamline inference for large language models, taking care of tasks like batching, token streaming, and model optimization behind the scenes. When run on the right hardware, TGI can deliver near real-time performance, even for models with billions of parameters.
AWS Inferentia2 is that hardware. Developed by AWS to handle deep learning inference, it offers high throughput with lower power use and cost. Combining TGI with Inferentia2 means you're getting more from the same models — faster and without the heavy price tag tied to GPUs.
At its core, TGI is a server optimized for running text generation tasks from Hugging Face Transformers models. But the real draw lies in how it handles these tasks. Here’s what makes it stand out:

Rather than waiting for the full output to finish before showing the result, TGI supports token streaming. So, users start seeing the generated text as soon as it begins. This feels faster and more responsive, even if the underlying model is heavy.
When multiple users make requests at once, TGI groups them into batches that run in a single forward pass. This improves efficiency without affecting how results are delivered. Static batching in TGI is predictable and removes the guesswork.
Need to run different models at once? TGI allows loading multiple models in parallel, assigning them to different ports or endpoints. This is especially useful for teams testing variants or offering several services under the same deployment.
This is a newer feature focused on memory efficiency. By merging repeated tokens during decoding, TGI reduces memory load and processing time. It’s a small trick with a big payoff for longer text outputs.
Getting TGI to work with AWS Inferentia2 involves a few steps, but the performance gains make it worthwhile. Here’s how to do it:
Start by launching an EC2 instance powered by AWS’s Inf2 instances. These are designed for high-throughput deep learning inference and are based on the Neuron SDK. Choose the size that matches your expected load — something like inf2.xlarge for testing or inf2.24xlarge for production.
Make sure to select a Deep Learning AMI with Neuron support or install the Neuron SDK manually if starting from a clean OS.
Once your instance is running, install the Hugging Face TGI server. You’ll need Python, PyTorch with Neuron backend, and text-generation inference from Hugging Face.
Use pip or build from source:
bash
CopyEdit
pip install text-generation-inference[neuron]
Or follow the Neuron-specific installation steps from Hugging Face’s GitHub repo for TGI to ensure everything aligns with the hardware.
Models trained with standard PyTorch won’t run directly on Inferentia2. You need to compile them for the Neuron backend.
Use Hugging Face Optimum-Neuron to convert:
python
CopyEdit
from optimum.neuron import NeuronModelForCausalLM
model = NeuronModelForCausalLM.from_pretrained("model-name", export=True)
This generates a Neuron-compatible version of the model. It’s a one-time setup per model unless you retrain or fine-tune.
Once your model is compiled, use TGI to serve it:
bash
CopyEdit
text-generation-launcher --model-id ./compiled-model --port 8080 --neuron
You can now send requests to your instance via the TGI REST API or integrate it into your application. Thanks to the way TGI is built, the server handles everything from token management to batch inference without needing constant tuning.
TGI with AWS Inferentia2 isn’t about squeezing performance out of old systems. It’s about giving modern models room to breathe without burning through compute credits. The big win here is cost per token. Compared to running the same inference on GPU-backed instances, Inferentia2 delivers similar performance at a significantly lower cost — especially at scale. This changes the math for startups and teams looking to serve language models in production without constantly watching their billing dashboards.
Another benefit is power efficiency. Inferentia2 chips use less power than GPUs to deliver similar throughput. This means fewer concerns around overheating or scaling across availability zones. Finally, the native integration with Hugging Face’s ecosystem is smooth. You can pull models directly from the Hub, compile them for Neuron, and deploy them with TGI in a few lines of code. It’s a setup that’s ready for teams who care more about output than babysitting infrastructure.
Hugging Face Text Generation Inference, when used with AWS Inferentia2, offers a real-world solution to a common bottleneck in running large language models. The blend of software optimized for text generation and hardware tailored for inference creates a space where developers can focus on building applications, not managing servers. It’s fast, cost-aware, and ready for production. If you’re running LLMs and looking for ways to keep them responsive and efficient, this setup might be the right fit.
Advertisement

xAI, Nvidia, Microsoft, and BlackRock have formed a groundbreaking AI infrastructure partnership to meet the growing demands of artificial intelligence development and deployment

Looking for simple ways to export and share your ChatGPT history? These 4 tools help you save, manage, and share your conversations without hassle

How Nvidia produces China-specific AI chips to stay competitive in the Chinese market. Learn about the impact of AI chip production on global trade and technological advancements

Rockwell Automation introduced its AI-powered digital twins at Hannover Messe 2025, offering real-time, adaptive virtual models to improve manufacturing efficiency and reliability across industries
Advertisement

How the AI-enhancing quantum large language model combines artificial intelligence with quantum computing to deliver smarter, faster, and more efficient language understanding. Learn what this breakthrough means for the future of AI

What data lakes are and how they work with this step-by-step guide. Understand why data lakes are used for centralized data storage, analytics, and machine learning

Curious about ChatGPT jailbreaks? Learn how prompt injection works, why users attempt these hacks, and the risks involved in bypassing AI restrictions
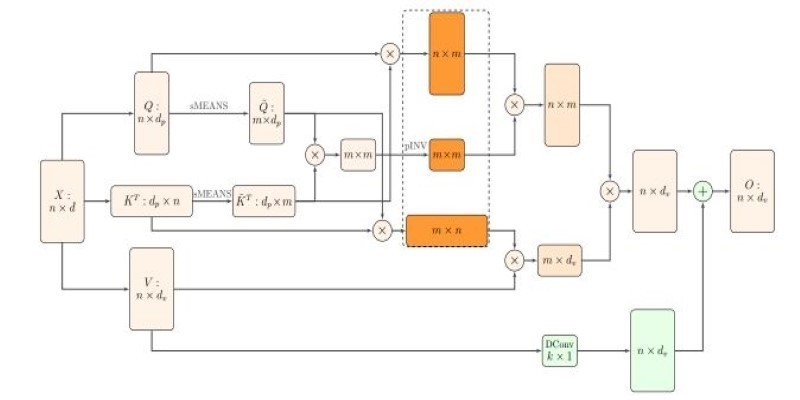
How Nyströmformer uses the Nystrmmethod to deliver efficient self-attention approximation in linear time and memory, making transformer models more scalable for long sequences
Advertisement

A leading humanoid robot company has introduced its next-gen home humanoid designed to assist with daily chores, offering natural interaction and seamless integration into home life

How the OpenAI jobs platform is changing the hiring process through AI integration. Learn what this means for job seekers and how it may reshape the future of work

Is self-driving tech still a future dream? Not anymore. Nvidia’s full-stack autonomous driving platform is now officially in production—and it’s already rolling into real vehicles

Learn how to use ChatGPT for customer service to improve efficiency, handle FAQs, and deliver 24/7 support at scale