Advertisement
Transformers are known for their strength in handling sequential data across various domains, from language modelling to image processing. However, this strength comes at a high computational cost. The self-attention mechanism at the heart of the transformer scales quadratically with the sequence length. This becomes a bottleneck when working with long sequences, especially in real-time or memory-constrained environments.
Over the past few years, many researchers have tried to tackle this problem, and one interesting approach stands out — the Nyströmformer. This model proposes an efficient way to approximate self-attention using the Nyström method, a technique rooted in numerical analysis, to reduce both memory and time complexity without losing much performance. Let’s explore how this method works and what it offers in practical settings.
Self-attention computes pairwise interactions between every token in the input. If your input is 1,000 tokens long, the model has to calculate one million interactions. That’s manageable with short inputs, but things spiral quickly as input size increases. This is why models like BERT or GPT tend to struggle when dealing with long sequences in a resource-efficient way.
This bottleneck is not just about speed; it's also about memory. Each interaction needs to be stored, and when sequence lengths grow into the tens of thousands, even storing the attention matrix becomes infeasible. Several low-rank or sparse approximations have been proposed, but most of them still require complex computations or don't generalize well to different tasks.
That’s where the Nyström method comes into the picture — not as a new idea, but as a repurposed one.
The Nyström method isn't originally from machine learning. It's a numerical technique for approximating large, positive, semi-definite matrices using a subset of their columns. The idea is to select a small number of representative samples and use them to approximate the entire matrix, saving both computation and memory.
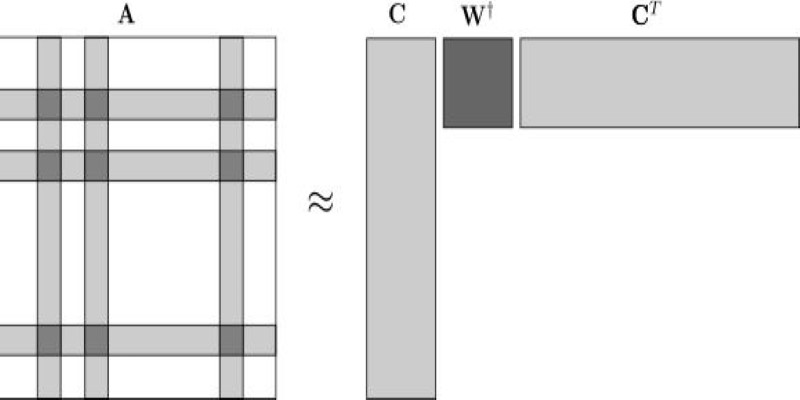
In the context of self-attention, the full attention matrix is a large matrix of similarity scores between all token pairs. The Nyströmformer picks a small number of landmark tokens — say, 32 or 64 out of a 1000-token sequence — and computes attention using only those. These landmarks help to reconstruct the full attention map through a low-rank approximation. It replaces the full matrix product with a sequence of smaller matrix operations that still preserve the structure of attention but at a fraction of the cost.
What makes this approach useful is that it maintains a decent level of accuracy while dramatically cutting down on the heavy lifting. It avoids the need to build sparse attention masks or split the input into chunks, which can cause context fragmentation.
The Nyströmformer takes the transformer’s attention matrix and breaks it into three parts: queries, keys, and values. Instead of using all queries and keys, it selects a small set of landmark points from the key space. It then uses these landmarks to approximate the full attention matrix.
The steps go roughly like this:
This process replaces the standard softmax attention with an approximation that scales linearly in time and space. For a sequence of length n and m landmark points, the complexity becomes O(nm) instead of O(n²). When m is much smaller than n, the savings are substantial.
The Nyströmformer also includes a few stabilizing steps, like using Moore-Penrose pseudoinverses and additional residual connections. These help reduce the approximation error and make the model more robust to variations in input length and data type.
One of the most significant strengths of the Nyströmformer is its ability to handle long sequences without segmenting the input. This makes it more natural for tasks like document classification, long-form question answering, or genome sequence analysis. You don't have to worry about losing context across segments, a common issue with chunked attention methods.

Another advantage is its relative simplicity. The method doesn’t require retraining the whole model from scratch or adding many new components. It swaps out the attention mechanism, so it can often be used as a drop-in replacement or incorporated into larger architectures with minor adjustments.
That said, no approximation is perfect. The Nyström method introduces some errors compared to full attention. While this loss is minimal in many tasks, especially those involving redundancy in the input, it might be noticeable in precision-heavy applications like mathematical reasoning or dense classification tasks. There's also a dependence on how landmark points are selected. Uniform sampling works reasonably well, but more informed selection strategies could improve performance — though at the cost of more complexity.
Compared to other efficient transformer models, such as Linformer, Performer, or BigBird, the Nyströmformer strikes a balance between simplicity and effectiveness. It doesn’t try to reinvent the entire architecture but instead makes one well-chosen modification that pays off in efficiency, delivering practical gains across a range of sequence lengths, tasks, and deployment environments with minimal added complexity.
The Nyströmformer provides a smart, efficient solution for applying transformer models to long-sequence tasks without the usual computational burden. Using the Nyström method for self-attention approximation cuts down on memory and time requirements while keeping performance solid. This isn't about replacing transformers but making them more practical and accessible where they were once too heavy to use. For those working with extended inputs in areas like document processing or sequence modelling, the Nyströmformer offers a clean, scalable path forward. It may not be the only method out there, but its mathematical clarity and simple implementation make it one of the more grounded, effective options available today.
Advertisement

How Gradio reached one million users by focusing on simplicity, openness, and real-world usability. Learn what made Gradio stand out in the machine learning community

Explore the concept of LeRobot Community Datasets and how this ambitious project aims to become the “ImageNet” of robotics. Discover when and how a unified robotics dataset could transform the field

ChatGPT Search just got a major shopping upgrade—here’s what’s new and how it affects you.

How Nvidia produces China-specific AI chips to stay competitive in the Chinese market. Learn about the impact of AI chip production on global trade and technological advancements
Advertisement

How Amazon S3 works, its storage classes, features, and benefits. Discover why this cloud storage solution is trusted for secure, scalable data management

Speed up Stable Diffusion Turbo and SDXL Turbo inference using ONNX Runtime and Olive. Learn how to export, optimize, and deploy models for faster, more efficient image generation

The future of robots and robotics is transforming daily life through smarter machines that think, learn, and assist. From healthcare to space exploration, robotics technology is reshaping how humans work, connect, and solve real-world challenges

Learn the top 8 Claude AI prompts designed to help business coaches and consultants boost productivity and client results.
Advertisement

Discover how Nvidia's latest AI platform enhances cloud GPU performance with energy-efficient computing.

xAI, Nvidia, Microsoft, and BlackRock have formed a groundbreaking AI infrastructure partnership to meet the growing demands of artificial intelligence development and deployment

How the OpenAI jobs platform is changing the hiring process through AI integration. Learn what this means for job seekers and how it may reshape the future of work

How AI is transforming traditional intranets into smarter, more intuitive platforms that support better employee experiences and improve workplace efficiency