Advertisement
The term might sound technical at first, but let’s break it down. Imagine a machine that can read, write, summarize, and even hold conversations — and do it in a way that sounds surprisingly human. That’s what a large language model does. It’s not just a smart chatbot or a fancy calculator. It's something that has studied more text than any one person could in a thousand lifetimes, and it uses that learning to answer questions, complete tasks, and, yes, sometimes even surprise the very people who created it.
But this isn't some sci-fi plot twist. LLMs are here, and they’re already being used in places you probably wouldn’t expect — like helping doctors interpret clinical notes or making customer support feel less robotic. To understand what makes them tick, though, we need to dig into how they work and why they’re so good at mimicking human language.
Let's begin with the "large" bit. In technical terms, it generally refers to the size of the number of parameters, i.e., the internal parameters that a model can modify as it learns data. Just imagine reading millions of books and not only remembering the definition of each word, but also how it connects with every other word in different subjects and moods. That is what LLMs do, and they do this by adjusting billions (and occasionally trillions) of these parameters.

But where do these models get their data? They’re trained on huge collections of text from books, websites, articles, and more. This means they’re absorbing grammar rules, sentence patterns, cultural references, slang, and formal writing — all at once. That’s why when you ask an LLM a question, it can respond in a way that often sounds natural and informed.
It’s also important to note that these models don’t “understand” in the way people do. They aren’t thinking or feeling — they’re predicting. Based on what they’ve seen before, they predict what should come next in a sentence. That’s how they write. That’s also how they answer questions, summarize content, and complete tasks.
Training an LLM isn’t a weekend project. It starts with something called pretraining. In this stage, the model is fed an enormous amount of text — no labels, no corrections, just raw data. The model’s goal? Predict the next word in a sentence. For example, if given “The cat sat on the,” it learns that “mat” might be a likely choice based on how often that phrase appears in books and articles.
As the model repeats this process billions of times, it begins to see patterns. It gets progressively more skilled at guessing what word to use next, and doing so makes it more skilled at language tasks overall.
Once that’s done, we move into fine-tuning. This is where the model gets more specific training. Instead of just predicting text, it's shown questions and answers, summaries, conversations — things that are closer to how we actually use it. This step helps shape the model’s output to be more useful, safer, and less likely to go off track.
Here’s where things get interesting. Once trained, LLMs become surprisingly versatile. You can ask them to:

And that's just scratching the surface. They're being integrated into apps, customer support, writing tools, programming assistants, and even educational platforms. Instead of needing separate software for grammar checking, translation, or content creation, a single LLM can handle all of it, simply by responding to text commands.
But the way they do it isn’t magic. Behind the scenes, the model is constantly calculating which words are most likely to come next. That’s how it forms sentences, ideas, and solutions. It doesn’t know if what it’s saying is true — it just knows what’s probable based on the patterns it has seen.
That’s also why LLMs can sometimes “hallucinate” — a term used when they generate false or made-up information. It’s not that they’re lying. They’re just producing the kind of text that looks right, even when it’s not. This is a known limitation and one of the areas researchers are actively working on improving.
All of this wouldn’t be possible without a type of architecture called a transformer. Introduced in 2017, transformers changed everything for language modeling. Before them, models struggled to understand long-range context. For example, they couldn’t connect the beginning of a paragraph to the end very well.
Transformers fixed that by introducing something called attention. This mechanism lets the model focus on specific words in a sentence, not just the ones right before the current word, but any word that might be relevant. Think of it like reading a novel and being able to instantly remember what happened in chapter two when you're halfway through chapter ten.
This ability to “pay attention” is what allows LLMs to keep context and generate coherent, meaningful responses across longer passages. Without it, conversations would feel broken and summaries would miss key points.
It’s also what makes these models capable of adapting to different tones and styles. They don’t just respond based on content — they also pick up on structure, word choice, and formatting. That’s why you can ask the same question in different ways and get responses that match your tone.
Large language models are one of the most significant advancements in how machines use and produce human language. They don’t think like us, and they don’t know like we do — but they’re trained to predict with a level of precision that often feels intuitive.
What makes them stand out isn’t just their ability to answer questions. It’s their adaptability. They can write a formal report, a joke, a recipe, or a set of instructions — all based on how you ask. That versatility is what’s pushing them into more and more areas of work and daily life.
Advertisement

ChatGPT Search just got a major shopping upgrade—here’s what’s new and how it affects you.

Intel and Hugging Face are teaming up to make machine learning hardware acceleration more accessible. Their partnership brings performance, flexibility, and ease of use to developers at every level

What happens when ML teams stop juggling tools? Fetch moved to Hugging Face on AWS and cut development time by 30%, boosting consistency and collaboration across projects

How the Philadelphia Eagles Super Bowl win was accurately predicted by AI, showcasing the growing role of data-driven analysis in sports outcomes
Advertisement

PaLM 2 is reshaping Bard AI with better reasoning, faster response times, multilingual support, and safer content. See how this powerful model enhances Google's AI tool
Explore Apache Kafka use cases in real-world scenarios and follow this detailed Kafka installation guide to set up your own event streaming platform
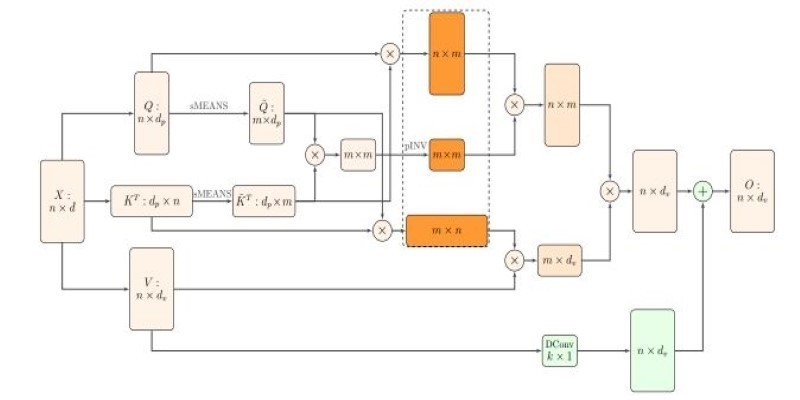
How Nyströmformer uses the Nystrmmethod to deliver efficient self-attention approximation in linear time and memory, making transformer models more scalable for long sequences

Explore the concept of LeRobot Community Datasets and how this ambitious project aims to become the “ImageNet” of robotics. Discover when and how a unified robotics dataset could transform the field
Advertisement

Tired of reinventing model workflows from scratch? Hugging Face offers tools beyond Transformers to save time and reduce boilerplate

Find how AI is reshaping ROI. Explore seven powerful ways to boost your investment strategy and achieve smarter returns.

Learn 5 simple steps to protect your data, build trust, and ensure safe, fair AI use in today's digital world.

Rockwell Automation introduced its AI-powered digital twins at Hannover Messe 2025, offering real-time, adaptive virtual models to improve manufacturing efficiency and reliability across industries