Advertisement
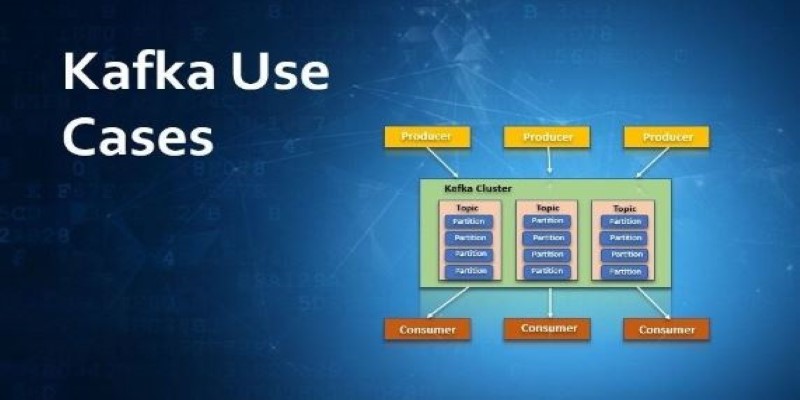
Apache Kafka is a distributed event streaming platform that manages high volumes of real-time data efficiently. Created by LinkedIn, Kafka has become a go-to tool for organizations looking to process continuous streams of records reliably. Unlike older messaging systems, it can store and replay data streams, which makes it especially useful when consistency and replayability are needed.
Many businesses use Kafka as the foundation for applications that depend on real-time data and fault-tolerant communication. This article explains some of the most common Apache Kafka use cases and provides a clear, step-by-step guide to installing it properly.
Apache Kafka shines in scenarios where data never stops flowing and decisions need to keep pace. One of its standout roles is driving real-time analytics pipelines. For example, retailers and online platforms stream live transaction and click data through Kafka into their analytics dashboards. This gives them a clear picture of sales trends, stock levels, and customer behavior as it happens, so they can react without waiting for overnight reports.
In the financial world, Kafka is key to spotting fraud and monitoring trades. Banks and payment networks send transaction streams into processing systems through Kafka, which helps identify unusual patterns in seconds and trigger immediate alerts. That level of responsiveness can make all the difference when security is on the line.
Kafka is also popular in microservices environments, where many small, independent services need to share information without being tightly coupled. Each service can publish events to Kafka and subscribe to the topics it cares about, staying aware of what’s happening elsewhere while staying autonomous. This makes systems more flexible and less prone to cascading failures.
For operations teams, Kafka simplifies log collection. Distributed applications generate logs from dozens or hundreds of servers, and Kafka can pull all of them into a central stream. From there, tools like Elasticsearch or Splunk can analyze and surface insights, making it easier to catch issues before they escalate.
Finally, Kafka is widely used for feeding data lakes. Organizations stream live operational data into big storage systems like Hadoop or cloud-based warehouses, avoiding the delays and strain of traditional batch uploads while keeping source systems responsive and fast.
Installing Kafka begins with a bit of preparation. Since Kafka runs on the Java Virtual Machine, Java 8 or newer needs to be installed. Kafka also requires ZooKeeper to coordinate broker metadata and leader elections, so you’ll need to plan for ZooKeeper as well. In testing environments, you can run both on the same machine. In production, it’s better to use at least three separate ZooKeeper nodes for reliability.
You should ensure your server has enough memory, CPU, and fast disks. Kafka’s performance depends heavily on disk speed and network bandwidth. It’s recommended to use SSDs for better throughput and to monitor disk space closely, since Kafka persists all messages on disk until they expire.
Plan a clear directory structure before starting. Kafka stores its log data in the directory defined by log.dirs in the configuration file. Choose a reliable and fast storage path for these files. Decide how many brokers you plan to run and how you’ll distribute them across your infrastructure. Even in development, it helps to start with a structure that resembles your intended production layout.
The actual installation of Apache Kafka is straightforward. Begin by downloading the latest release from the official Apache Kafka site. Extract the tar or zip file to your chosen directory.
Start by running ZooKeeper. Kafka ships with a basic ZooKeeper configuration in config/zookeeper.properties. Use the command:
bin/zookeeper-server-start.sh config/zookeeper.properties
This will start ZooKeeper on the default port. With ZooKeeper running, you can start a Kafka broker. Edit the file config/server.properties if you want to change defaults like broker.id, log.dirs, or the listener address. Then launch the broker with:
bin/kafka-server-start.sh config/server.properties
Kafka is now running and ready to handle data. You can create a topic using the built-in script:
bin/kafka-topics.sh --create --topic test-topic --bootstrap-server localhost:9092 --partitions 1 --replication-factor 1
Verify the setup by producing and consuming a few messages. Use the producer console to send data:
bin/kafka-console-producer.sh --topic test-topic --bootstrap-server localhost:9092
And open a separate terminal to consume those messages:
bin/kafka-console-consumer.sh --topic test-topic --from-beginning --bootstrap-server localhost:9092
In a production environment, you should configure multiple brokers, each with its own broker.id, and point them all to the same ZooKeeper ensemble. You can also tune replication and partitioning based on how much fault tolerance and throughput you need.
Kafka supports secure connections and authentication, but these are disabled by default. Once you’ve confirmed the installation works, you can turn on SSL encryption and SASL authentication to secure your cluster. This requires updating both broker and client configurations.
Once installed, Kafka needs ongoing monitoring and maintenance to ensure smooth operation. Monitoring disk usage, broker uptime, and ZooKeeper health is necessary, since running out of space or losing quorum can cause data loss or outages. Tools like Prometheus and Grafana are commonly used to visualize Kafka metrics.

Retention policies should be configured carefully. Kafka allows you to define how long messages stay in a topic or how much disk space they can consume. Cleaning up unused topics and monitoring under-replicated partitions will keep the cluster stable.
Regular backups of configurations and careful version upgrades are also part of maintaining a healthy Kafka deployment. Rolling upgrades are supported but should be tested in a staging environment before applying to production.
Apache Kafka has become a preferred choice for organizations that need reliable, high-throughput event streaming. Its ability to handle real-time analytics, enable microservices, aggregate logs, and ingest data into lakes makes it versatile and dependable. Setting it up involves installing Java, configuring ZooKeeper, starting brokers, and creating topics, which can all be done with a few well-defined commands. Once installed, keeping it monitored and properly configured ensures it continues to deliver reliable performance over time. With thoughtful planning and maintenance, Kafka can handle the demands of modern data-driven applications with ease.
Advertisement

How the Bamba: Inference-Efficient Hybrid Mamba2 Model improves AI performance by reducing resource demands while maintaining high accuracy and speed using the Mamba2 framework

How AI in real estate is redefining how properties are bought, sold, and managed. Discover 10 innovative companies leading the shift through smart tools and data-driven decisions

Ahead of the curve in 2025: Explore the top data management tools helping teams handle governance, quality, integration, and collaboration with less complexity

IBM Plans $150B Technology Investment in US, focusing on semiconductors, AI, quantum computing, and workforce development to strengthen innovation and create jobs nationwide
Advertisement

AI content detectors don’t work reliably and often mislabel human writing. Learn why these tools are flawed, how false positives happen, and what smarter alternatives look like

Yamaha launches its autonomous farming division to bring smarter, more efficient solutions to agriculture. Learn how Yamaha robotics is shaping the future of farming

Discover 7 Claude AI prompts designed to help solo entrepreneurs work smarter, save time, and grow their businesses fast.

What happens when two tech giants team up? At Nvidia GTC 2025, IBM and Nvidia announced a partnership to make enterprise AI adoption faster, more scalable, and less chaotic. Here’s how
Advertisement

Discover how Nvidia's latest AI platform enhances cloud GPU performance with energy-efficient computing.

How the AI-enhancing quantum large language model combines artificial intelligence with quantum computing to deliver smarter, faster, and more efficient language understanding. Learn what this breakthrough means for the future of AI

Running large language models at scale doesn’t have to break the bank. Hugging Face’s TGI on AWS Inferentia2 delivers faster, cheaper, and smarter inference for production-ready AI

Tired of reinventing model workflows from scratch? Hugging Face offers tools beyond Transformers to save time and reduce boilerplate